
Bloggen til Anders Løland
Gode sommerdekk?
mars 16, 2012 - 09:18 — Anders Løland
NAF har prisverdig nok også i år testet sommerdekk for oss. VG kan melde at «Nokian (Finland) og Pirelli (Italia) deler førsteplassen med Hankook - alle med 9,2 av 10 poeng».
Det stemmer sikkert, selv om slike tester også har et subjektivt element. Detaljene fra testen gjør NAF rede for på sitt eget nettsted.
Jeg gjengir for enkelhets skyld sluttresultatene per dekk:
Her kan vi for eksempel lese at vi bør holde oss unna BF Goodrich, som bare får 6,2 poeng, mot 9,2 poeng for de tre vinnerne. 9,2 er like under 10 og selv 6,2 poeng av 10 høres vel ikke så verst ut? I avveiningen mellom pris og nytte (der du har laget deg en såkalt nyttefunksjon), kan det godt være at BF Goodrich eller Jinyu er gode nok for deg, gitt at dekkene er billige nok.
Pussig nok er det ikke snakk om 9,2 eller 6,2 poeng av 10, men 6,2 på en skala fra 4 til 10 poeng (som NAF gjør oppmerksom på i sin tabelltekst). Det er derfor ikke mulig å få færre enn 4 poeng. Hvis vi derfor regner om poengene til prosent (hvor 0% er minimum og 100% er maksimum!) får vi en ny tabell:
Nå er det straks mye klarere hvor forskjellige dekkene er. Testens tre vinnere har et stykke opp til full score. De tre dårligste dekkene er ikke nokså gode, som NAFs poengskala ga inntrykk av. Valget mellom et dekk som scorer 6,2 poeng og 37 % er enkelt, problemet er at det er det samme dekket! Det kan forkludre kundens avveining mellom pris og kvalitet.
Den noe uvanlige poengskalaen over føyer seg inn i en god trikse-med-skala-tradisjon. Allerede i 1954 ga Darrell Huff ut «How to Lie with Statistics», som fortsatt selger godt.
| Anders Løland |
Foto: Lin Stenstrud Jeg tok hovedfag i anvendt og industriell matematikk på Blindern i 1999, og jobbet deretter i et par år med sonardata ved Forsvarets forskningsinstitutt (FFI) på Kjeller. Siden 2001 har jeg jobbet ved NR. På fritida liker jeg å løpe oppover bratte bakker. Jeg heier på Hønefoss, som kommer til å imponere i eliteserien i år. |

Hvor raskt er det mulig å løpe 200 m?
juni 7, 2011 - 15:08 — Anders LølandPå torsdag skal Usain Bolt løpe 200 m i Bislett Games. Med en verdensrekord på utrolige 19,19 kan en spørre seg: Hva er den ultimate 200 m-rekorden?
En måte å svare på dette er å benytte såkalt statistisk-matematisk ekstremverditeori, som handler om sannsynligheten for ekstreme hendelser, som flom, hundreårsbølger eller krakk i aksjemarkedet. I ekstremverditeori ser en spesielt på de mest ekstreme hendelsene, og forsøker å si noe om hvor mye bedre/verre det kan gå. Dette er helt uvurderlig kunnskap når en for eksempel skal bygge et skip eller en oljeplattform som skal tåle en hundreårsbølge.
200 m
For noen år siden tok to nederlandske forskere for seg 780 personlige bestetider på 200 m, og anslo at den ultimate verdensrekorden på 200 m er 18,63. Til sammenligning påstod den tidligere sprinteren Donovan Bailey i mandagens Aftenposten at Bolt kan løpe på 18,95 på torsdag.
100 m
I den samme studien konkluderte forskerne med at den ultimate 100 m-rekorden er så god som 9,29. Baileys 100 m-anslag er den litt mindre optimistiske tiden 9,4.
Er slike utsagn fra forskere til å stole på? I teorien er de det, og oljeplattformene står fortsatt, selv om usikkerheten naturlig nok er ganske stor. I tillegg til den metodiske usikkerheten er det usikkerhet knyttet til datagrunnlaget. Nettopp på grunn av det kom det i år en ny analyse av den ultimate 100 m-rekorden, igjen med samme hovedforfatter som sist. I 1990 innførte IAAF (det internasjonale friidrettsforbundet) dopingkontroller utenfor konkurranse. For å ekskludere mulige dopede bestetider, så derfor forfatterne bort fra noteringer før 1991. Med et bedre datagrunnlag og forbedrede metoder, fant de ut at den ultimate 100-m-rekorden er 9,51 (og ikke 9,29). Merk at Bolts siste 100 m-verdensrekord ikke var en del av datagrunnlaget, men ifølge nederlenderne vil det ikke påvirke analysen i særlig stor grad.
200 m igjen
Dette kan altså tyde på at det tidligere anslaget på 18,63 er vel optimistisk. Hvis vi grovt justerer med to ganger forskjellen i ultimate 100 m-tider (9,51 − 9,29 = 0,22), får vi 18,63 + 0,44 = 18,99. Kort oppsummert er vi og Bailey enige i at den ultimate 200 m-tiden kanskje er like under 19 blank.
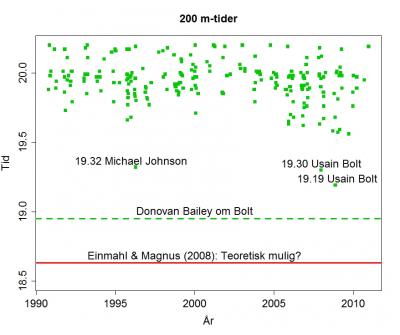
Figuren viser de beste tidene de siste tjue årene, samt mulige bestetidsgrenser. Det har kanskje vært en svak forbedring av gjennomsnittsnivået til de beste over tid. Legg merke til hvor spesielt gode Michael Johnsons beste og Usain Bolts to beste tider er i forhold til resten av feltet.
Referanser
John H. J. Einmahl og Sander G. W. R. Smeets (2011)
Ultimate 100-m world records through extreme-value theory
Statistica Neederlandica 65(1) , s. 32-42
John H. J. Einmahl og Jan R. Magnus (2008)
Records in Athletics Through Extreme-Value Theory
Journal of the American Statistical Association 103(484), s. 1382-1391
| Anders Løland |
Foto: Lin Stenstrud Jeg tok hovedfag i anvendt og industriell matematikk på Blindern i 1999, og jobbet deretter i et par år med sonardata ved Forsvarets forskningsinstitutt (FFI) på Kjeller. Siden 2001 har jeg jobbet ved NR. På fritida liker jeg å løpe oppover bratte bakker. Jeg heier på Hønefoss, som kommer til å imponere i eliteserien i år. |
Tidenes favorittstatistiker?
mars 21, 2011 - 10:55 — Anders LølandEn gang i uka har vi felleslunsj i vårt senter for forskningsdrevet innovasjon (sfi2), hvor vi kan dele idéer og diskutere prosjekter.
I vår har vi krydret lunsjene med en uformell kåring av tidenes favorittstatistiker. Vi gikk systematisk til verks og tok utgangspunkt i en kronologisk liste med 16 kandidater. I første lunsj kåret vi en vinner blant de første 4 kandidatene, og så videre. Etter fire lunsjer var det klart for en finale bestående av fire herrer, som representerer hver sin tidsepoke.
GAUSS, Carl Friedrich 1777-1855
Gauss var en vitenskapelig tusenkunstner. Som statistiker har han fått en stor del av æren for minste kvadraters metode (hvordan trekke en linje gjennom data på beste måte), og ikke minst normalfordelingen (eller Gausskurven). Normalfordelingen er statistikerens viktigste verktøy, og dukker (heldigvis) ofte opp i naturen. En veldig viktig grunn til det er det nesten magiske sentralgrenseteoremet, som Gauss riktignok ikke kan ta æren for. Det kan de Moivre, men han kom ikke med på vår eksklusive liste.
MARKOV, Andrei Andreevich 1856-1922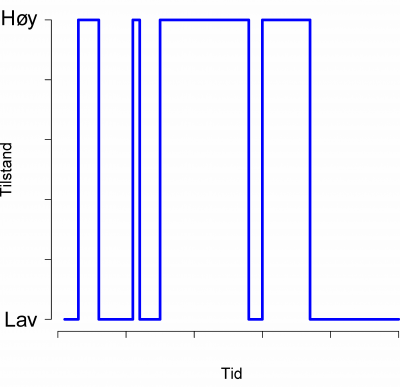
Den godeste Markov er mest kjent for kjeder, altså Markovkjeder. I en Markovkjede trenger du bare å kjenne til forrige tilstand for å si noe om utviklingen framover (som i figuren). Denne egenskapen har vist seg å være veldig nyttig innen mange felt, for eksempel for å studere aksjemarkeder som skifter mellom høy og lav usikkerhet.
FISHER, Sir Ronald Aylmer 1890-1962
Biologen Richard Dawkins har kalt Fisher for “den største av Darwins etterfølgere”. Fisher har lagt grunnlaget for skummelt mye av moderne statistisk-matematisk metode. Hans bidrag inkluderer hvordan ukjente parametre i en modell skal estimeres, variansanalyse, forsøksplanlegging og randomisering: skal du teste ut en ny medisin må du ha en kontrollgruppe, og du må trekke tilfeldig hvem som skal behandles og ikke.
EFRON, Bradley 1938-
Efrons største bidrag er nok bootstrap-metoden, som er omtrent like magisk som å løfte seg selv etter støvelstroppene. Mens Fisher & kompani etter lange utledninger kom til hvor usikker en estimert størrelse er, viste Efron at en kan få bedre resultater ved å la datamaskinen trekke tilfeldige blandinger av dataene.
Personlig rangerer jeg Fisher høyest, med Efron på en god annenplass. Flertallet av lunsjdeltakerne ville det annerledes. Fisher måtte se seg knepent slått av Gauss i finalen.
Her kan du finne alle kandidatene og delvinnerne fra vår uformelle kåring.
| Anders Løland |
Foto: Lin Stenstrud Jeg tok hovedfag i anvendt og industriell matematikk på Blindern i 1999, og jobbet deretter i et par år med sonardata ved Forsvarets forskningsinstitutt (FFI) på Kjeller. Siden 2001 har jeg jobbet ved NR. På fritida liker jeg å løpe oppover bratte bakker. Jeg heier på Hønefoss, som kommer til å imponere i eliteserien i år. |
Kan statistikere spille Lotto?
november 9, 2010 - 09:48 — Anders LølandFor en tid tilbake raljerte jeg over hvor håpløst det er å spille Lotto. Til tross for det, spiller jeg av og til.
Min bortforklaring kommer her: En ukentlig innsats på 20 kroner er så lite at jeg ser bort fra den. (I tillegg går jo Norsk Tippings overskudd til en god sak.) Å vinne førstepremien, derimot, hadde unektelig vært ganske kjekt. Så til tross for at Lotto nesten helt sikkert er et tapsprosjekt, ser jeg bort fra tapet og fokuserer ensidig på den mulige gevinsten.
For å vitenskapligfisere dette enda litt mer, har jeg laget min egen nyttefunksjon. En nyttefunksjon tallfester en aktørs nytte av noe. I mitt tilfelle har jeg null nytte av Lotto-innsatsen i seg selv, mens jeg har en temmelig positiv nytte av en høy gevinst.
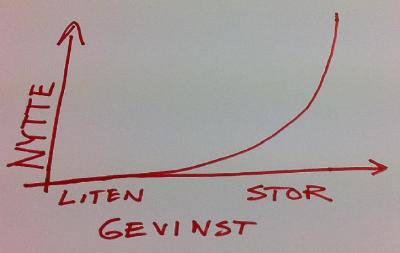
Dersom jeg hadde vært litt mer rasjonell, ville min forventning vært negativ:
forventet gevinst = –innsats + sannsynlighet for gevinst x gevinst < 0.
Med min nyttefunksjon får jeg en positiv forventet nytte:
forventet nytte = –nytte av innsats + sannsynlighet for gevinst x nytte av gevinst
= 0 + sannsynlighet for gevinst x nytte av gevinst > 0,
siden jeg ser bort fra innsatsen.
Nyttefunksjoner brukes ofte i økonomisk teori, for eksempel til å regne på og forklare hvilke valg vi (rasjonelle?) forbrukere gjør.
Nyttefunksjonens slektning brukes også i statistisk-matematisk modellering. Da kalles de slående nok tapsfunksjoner. Her vil en typisk at en modell skal være så god som mulig, med andre ord minimere tapsfunksjonen.
Det er ikke alltid åpenbart hvilken tapsfunksjon en skal velge. Dette henger igjen sammen med det såkalte "Ockhams barberkniv"-prinsippet: Med to mulige, men like gode, forklaringer, er det mest sannsynlig at den enkleste er best.
I mitt tilfelle er det uansett klart at min Lotto-nyttefunksjon er en funksjon som med høy sannsynlighet garanterer tap.
| Anders Løland |
Foto: Lin Stenstrud Jeg tok hovedfag i anvendt og industriell matematikk på Blindern i 1999, og jobbet deretter i et par år med sonardata ved Forsvarets forskningsinstitutt (FFI) på Kjeller. Siden 2001 har jeg jobbet ved NR. På fritida liker jeg å løpe oppover bratte bakker. Jeg heier på Hønefoss, som kommer til å imponere i eliteserien i år. |
Tålmodighetsprøven Lotto
august 11, 2010 - 11:35 — Anders Løland Her om dagen fikk jeg et spørsmål om Lotto:
Her om dagen fikk jeg et spørsmål om Lotto:
Øker vinnersjansen min hvis jeg ikke vant i forrige uke? Øker sjansen hvis jeg ikke har vunnet på ti år?
Spørsmålsstilleren vil nok være anonym, så jeg kaller ham Lotto-Lars. Lotto-Lars så for seg at sjansen øker hvis det er lenge siden forrige gevinst, siden det jevner seg ut i det lange løp. Det stemmer at det jevner seg ut i det lange løp, men dessverre for Lotto-Lars er vinnersjansen den samme hver uke og uavhengig av forrige ukes resultater: Hver uke begynner spillet på nytt.
Hvis Lotto-Lars ikke får noe igjen for at han ikke har vunnet på lenge, hvor lenge må han egentlig regne med å vente på den store gevinsten?
Sjansen for å vinne på en rekke i en Lotto-trekning er 1 av 5 379 616 (cirka 0,000 02 %). Lotto-Lars spiller 10 rekker i uka. Da må Lotto-Lars regne med å vente
537 961,6 uker
eller
10 345 år (hvis det er 52 uker i året) på sju rette!
Lotto-Lars kan være heldig og vinne allerede neste uke, men han kan også være uheldig og måtte vente lenge, lenge. Spesielt fortærende er det nok at han ikke får igjen for å ikke å ha vunnet tidligere.
Kanskje hjelper det litt med trøstepremien (4 rette + 1 tilleggstall), hvor vinnersannsynligheten er omtrent 0,6 %. Den vil Lotto-Lars i gjennomsnitt vinne hver 17. uke.
| Anders Løland |
Foto: Lin Stenstrud Jeg tok hovedfag i anvendt og industriell matematikk på Blindern i 1999, og jobbet deretter i et par år med sonardata ved Forsvarets forskningsinstitutt (FFI) på Kjeller. Siden 2001 har jeg jobbet ved NR. På fritida liker jeg å løpe oppover bratte bakker. Jeg heier på Hønefoss, som kommer til å imponere i eliteserien i år. |