
sannsynlighet
Friidretts-VM: Lurt å være god og ustabil!
september 2, 2011 - 16:04 — Frode Georgsen
I disse dager samles verdenseliten i friidrett i Daegu i Sør-Korea for å kjempe om tittelen «verdensmester» i ulike grener. For statistikere er friidrett en drømmeidrett med nesten ubegrenset tilgang på tall og statistiker. Norges eneste reelle gullhåp er spydkaster Andreas Thorkildsen. Siden han slo igjennom i OL i Athen i 2004, har han stort sett levert varene med 2 OL-gull, 2 EM-gull og 1 VM-gull. Thorkildsen har vunnet så mye i disse årene fordi han har vært den kasteren med det høyeste nivået. Et høyt gjennomsnittsnivå vil imidlertid ikke nødvendigvis føre til seier.
Det spesielle med kastøvelsene, og også lengde og tresteg, er at det ikke er stabilitet og gjennomsnittsresultat som er avgjørende. Den som har det ene lengste kastet (eller hoppet) av seks forsøk vinner, uavhengig av resultat i de andre forsøkene. (Vi ser for enkelthets skyld bort fra at utøverne i et mesterskap må gjennom kvalifisering og at de må sørge for å være blant de åtte beste etter tre forsøk for å få fullføre.) Gitt et bestemt gjennomsnittsnivå, er det da ideelt å ha størst mulig spredning i resultatene. Med andre ord; det er lurt å være god og ustabil.
Best av seks
Vi kan se på resultatet i denne type konkurranser som den maksimalt oppnådde lengden av seks uavhengige forsøk. Lengden i hvert forsøk følger en sannsynlighetsfordeling med en forventning (gjennomsnittsresultat over tid) og et standardavvik (spredning rundt gjennomsnittsresultatet). Denne sannsynlighetsfordelingen kan for eksempel være normalfordelingen, som følger den kjente Gausskurven.
Da Andreas Thorkildsen i fjor vant EM i Barcelona, hadde han ikke det beste gjennomsnittsresultatet (85,72 meter mot Matthias De Zordo med 86,30 meter), og hans nest beste kast var bare konkurransens 5. beste. Men han vant likevel fordi han hadde det lengste kastet på 88,37 meter. Ser vi på spredningen i Thorkildsens fem gyldige kast var standardavviket på 1,98 meter, mens De Zordo hadde 1,59 meter. Et høyt standardavvik tilsier at sjansen for å kaste dårlig er større, men det er også sjansen for et skikkelig langt kast. Det kan være nok for å vinne heder, ære og gull.
Thorkildsen over 90 meter?
Ser vi på alle OL, VM og EM fra 2004 til nå, har Andreas Thorkildsen gjennomsnittlig kastet 85,36 meter. Dersom vi sier at dette er et rimelig anslag på hans forventede resultat i et enkelt kast, vil vi også være interessert i spredningen. Med et standardavvik på 0, vil sluttresultatet garantert bli 85,36 meter. Det vil sannsynligvis ikke holde til gull. Nå har Andreas Thorkildsen faktisk et standardavvik i løpet av perioden på 3,07 meter. Sannsynligheten for at han da skal klare 90 meter i løpet av seks kast er 33%. Ingen andre i verden har kastet så langt i år. Thorkildsens argeste konkurrent i perioden 2004-2011, finske Tero Pitkämäki, har et lavere gjennomsnittsresultat (83,12 meter), men han kan håpe at hans litt høyere ustabilitet skal hjelpe ham (standardavvik på 3,16 meter). Dette er bare marginalt bedre enn Andreas Thorkildsen, og hans sannsynlighet for å kaste 90 meter er kun 10%. Vel så interessant er sannsynligheten for at Tero Pitkämäki slår Andreas Thorkildsen. Denne er på 22%.
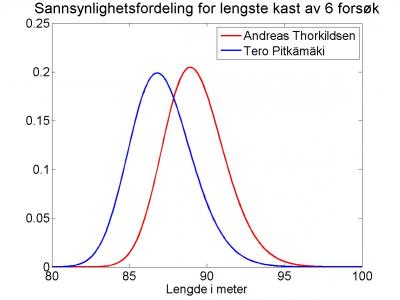
Figuren viser sannsynlighetsfordelingen for sluttresultatet (det lengste kastet) av seks forsøk for henholdsvis Andreas Thorkildsen og Tero Pitkämäki. Ser man nøye på den, ser man at den ikke følger en symmetrisk Gausskurve, men har et tyngdepunkt litt forskjøvet mot høyre.
Ved å ta med historiske resultater for flere utøvere, vil man se at Andreas Thorkildsen ofte vinner ikke bare fordi han er god, men også fordi han er blant de med størst spredning i kastlengdene.
Den enkle analysen over kan utvides ved for eksempel å ta hensyn til sannsynligheten for ugyldig kast, eller at utøverne blir slitne utover i konkurransen.
Heldigvis for oss som liker spennende sport, skal konkurransen avgjøres på banen og ikke via datamaskinens beregninger av matematiske modeller. Dermed kan (nesten) alt skje.

| Frode Georgsen |
Jeg er seniorforsker ved Norsk Regnesentral og jobber på den avdelingen (SAND) som driver med statistisk og matematisk modellering av geologi i olje- og gassreservoarer. Jeg er utdannet statistiker ved Universitetet i Oslo. I tillegg spiller jeg tuba og er sportsidiot. Spesielt er jeg interessert i skøyter og friidrett, og liker å se på sport på toppnivå og utøve sport på middelmådig nivå. Disse interessene må imidlertid tilpasses til at jeg også er gift og har tre barn. |

Hvor raskt er det mulig å løpe 200 m?
juni 7, 2011 - 15:08 — Anders LølandPå torsdag skal Usain Bolt løpe 200 m i Bislett Games. Med en verdensrekord på utrolige 19,19 kan en spørre seg: Hva er den ultimate 200 m-rekorden?
En måte å svare på dette er å benytte såkalt statistisk-matematisk ekstremverditeori, som handler om sannsynligheten for ekstreme hendelser, som flom, hundreårsbølger eller krakk i aksjemarkedet. I ekstremverditeori ser en spesielt på de mest ekstreme hendelsene, og forsøker å si noe om hvor mye bedre/verre det kan gå. Dette er helt uvurderlig kunnskap når en for eksempel skal bygge et skip eller en oljeplattform som skal tåle en hundreårsbølge.
200 m
For noen år siden tok to nederlandske forskere for seg 780 personlige bestetider på 200 m, og anslo at den ultimate verdensrekorden på 200 m er 18,63. Til sammenligning påstod den tidligere sprinteren Donovan Bailey i mandagens Aftenposten at Bolt kan løpe på 18,95 på torsdag.
100 m
I den samme studien konkluderte forskerne med at den ultimate 100 m-rekorden er så god som 9,29. Baileys 100 m-anslag er den litt mindre optimistiske tiden 9,4.
Er slike utsagn fra forskere til å stole på? I teorien er de det, og oljeplattformene står fortsatt, selv om usikkerheten naturlig nok er ganske stor. I tillegg til den metodiske usikkerheten er det usikkerhet knyttet til datagrunnlaget. Nettopp på grunn av det kom det i år en ny analyse av den ultimate 100 m-rekorden, igjen med samme hovedforfatter som sist. I 1990 innførte IAAF (det internasjonale friidrettsforbundet) dopingkontroller utenfor konkurranse. For å ekskludere mulige dopede bestetider, så derfor forfatterne bort fra noteringer før 1991. Med et bedre datagrunnlag og forbedrede metoder, fant de ut at den ultimate 100-m-rekorden er 9,51 (og ikke 9,29). Merk at Bolts siste 100 m-verdensrekord ikke var en del av datagrunnlaget, men ifølge nederlenderne vil det ikke påvirke analysen i særlig stor grad.
200 m igjen
Dette kan altså tyde på at det tidligere anslaget på 18,63 er vel optimistisk. Hvis vi grovt justerer med to ganger forskjellen i ultimate 100 m-tider (9,51 − 9,29 = 0,22), får vi 18,63 + 0,44 = 18,99. Kort oppsummert er vi og Bailey enige i at den ultimate 200 m-tiden kanskje er like under 19 blank.
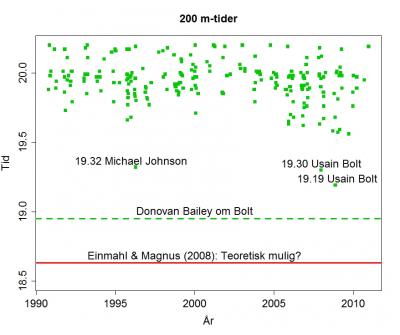
Figuren viser de beste tidene de siste tjue årene, samt mulige bestetidsgrenser. Det har kanskje vært en svak forbedring av gjennomsnittsnivået til de beste over tid. Legg merke til hvor spesielt gode Michael Johnsons beste og Usain Bolts to beste tider er i forhold til resten av feltet.
Referanser
John H. J. Einmahl og Sander G. W. R. Smeets (2011)
Ultimate 100-m world records through extreme-value theory
Statistica Neederlandica 65(1) , s. 32-42
John H. J. Einmahl og Jan R. Magnus (2008)
Records in Athletics Through Extreme-Value Theory
Journal of the American Statistical Association 103(484), s. 1382-1391
| Anders Løland |
Foto: Lin Stenstrud Jeg tok hovedfag i anvendt og industriell matematikk på Blindern i 1999, og jobbet deretter i et par år med sonardata ved Forsvarets forskningsinstitutt (FFI) på Kjeller. Siden 2001 har jeg jobbet ved NR. På fritida liker jeg å løpe oppover bratte bakker. Jeg heier på Hønefoss, som kommer til å imponere i eliteserien i år. |

Kan statistikere spille Lotto?
november 9, 2010 - 09:48 — Anders LølandFor en tid tilbake raljerte jeg over hvor håpløst det er å spille Lotto. Til tross for det, spiller jeg av og til.
Min bortforklaring kommer her: En ukentlig innsats på 20 kroner er så lite at jeg ser bort fra den. (I tillegg går jo Norsk Tippings overskudd til en god sak.) Å vinne førstepremien, derimot, hadde unektelig vært ganske kjekt. Så til tross for at Lotto nesten helt sikkert er et tapsprosjekt, ser jeg bort fra tapet og fokuserer ensidig på den mulige gevinsten.
For å vitenskapligfisere dette enda litt mer, har jeg laget min egen nyttefunksjon. En nyttefunksjon tallfester en aktørs nytte av noe. I mitt tilfelle har jeg null nytte av Lotto-innsatsen i seg selv, mens jeg har en temmelig positiv nytte av en høy gevinst.
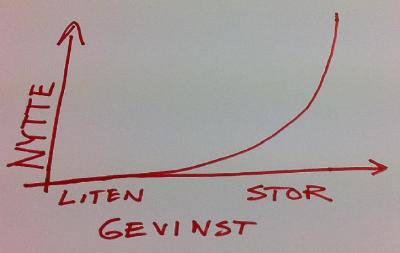
Dersom jeg hadde vært litt mer rasjonell, ville min forventning vært negativ:
forventet gevinst = –innsats + sannsynlighet for gevinst x gevinst < 0.
Med min nyttefunksjon får jeg en positiv forventet nytte:
forventet nytte = –nytte av innsats + sannsynlighet for gevinst x nytte av gevinst
= 0 + sannsynlighet for gevinst x nytte av gevinst > 0,
siden jeg ser bort fra innsatsen.
Nyttefunksjoner brukes ofte i økonomisk teori, for eksempel til å regne på og forklare hvilke valg vi (rasjonelle?) forbrukere gjør.
Nyttefunksjonens slektning brukes også i statistisk-matematisk modellering. Da kalles de slående nok tapsfunksjoner. Her vil en typisk at en modell skal være så god som mulig, med andre ord minimere tapsfunksjonen.
Det er ikke alltid åpenbart hvilken tapsfunksjon en skal velge. Dette henger igjen sammen med det såkalte "Ockhams barberkniv"-prinsippet: Med to mulige, men like gode, forklaringer, er det mest sannsynlig at den enkleste er best.
I mitt tilfelle er det uansett klart at min Lotto-nyttefunksjon er en funksjon som med høy sannsynlighet garanterer tap.
| Anders Løland |
Foto: Lin Stenstrud Jeg tok hovedfag i anvendt og industriell matematikk på Blindern i 1999, og jobbet deretter i et par år med sonardata ved Forsvarets forskningsinstitutt (FFI) på Kjeller. Siden 2001 har jeg jobbet ved NR. På fritida liker jeg å løpe oppover bratte bakker. Jeg heier på Hønefoss, som kommer til å imponere i eliteserien i år. |
Norge til fotball-EM?
september 10, 2010 - 15:20 — Magne AldrinNå er EM-kvalifiseringen i fotball godt i gang, og da klarer ikke vi å holde oss helt unna. Etter de første kampene har vi regnet oss fram til at Norge er favoritt i sin gruppe. Hvordan kan vi si det?
I utgangspunktet har en fotballkamp et element av både ferdighet og tilfeldighet. Et godt lag vil ofte slå et dårligere lag, men ikke alltid.
For å beskrive dette bruker vi en statistisk modell hvor hvert enkelt lag har et styrketall. Styrketallene til hvert lag tallfestes ut fra FIFA-rankingen, og av de fem lagene i Norges gruppe har i øyeblikket (8.9.2010) Portugal best FIFA-ranking, fulgt av Norge og Danmark. Norge er med andre ord et bedre lag enn Danmark ifølge FIFA-rankingen. Styrketallet til Portugal er fastsatt til 100. Vi tar også høyde for hjemmebanefordelen.
Styrketall per lag
|
Lag |
Styrketall |
|---|---|
|
Portugal |
100 |
|
Norge |
88 |
|
Danmark |
83 |
|
Kypros |
70 |
|
Island |
63 |
Et lite sidespor: Dette er litt forskjellig fra VM-beregningene våre, hvor vi (heldigvis) kom fram til at Spania lå best an før mesterskapet. I VM var det ingen hjemmebanefordel (bortsett fra for Sør-Afrika), og vi baserte oss på eksperttips istedenfor den noe omdiskuterte FIFA-rankingen.
Tilbake til EM: Etter at styrketallene er tallfestet, simulerer eller ”spiller” vi de resterende kampene i gruppa på en datamaskin. Deretter beregner vi tabellplasseringa til hvert enkelt. Tabellplasseringa bestemmes først av antall poeng, deretter av målforskjell, antall skårede mål og antall skårede mål på bortebane. Om to eller flere lag da står likt gjelder tilsvarende for innbyrdes oppgjør. Utfallet av hver kamp er tilfeldig, derfor blir det også i noe grad tilfeldig hvem som vinner gruppa i vårt simulerte gruppespill.
I virkeligheten spilles kampene kun én gang, men for å få fram det tilfeldige elementet gjentar vi vår øvelse 5 000 ganger. For hver gang registrerer vi H-U-B for hver enkelt kamp, og hvilket lag som kommer på de enkelte plassene til slutt. Ut fra dette beregner vi sannsynligheter for hvert enkelt lags muligheter. For eksempel beregnes sjansen for førsteplass ved å telle opp antall førsteplasser og dele på 5 000.
Vi har beregnet at Norges sjanser til å klare førsteplassen per i dag er 56 %, mens det er 26% sjanse for at Norge havner på andreplass (se tabellen). Hvis vi skjønnsmessig sier at det er 5/9=55% sjanse for å gå til EM med andreplass (fem av ni gruppetoere blir kvalifisert) gir det per i dag 70% sjanse for at Norge kvalifiserer seg til EM.
Sjanse for H-U-B per kamp
|
Hjemmelag |
Bortelag |
H (%) |
U (%) |
B (%) |
|---|---|---|---|---|
|
Kypros |
Norge |
29 |
26 |
45 |
|
Portugal |
Danmark |
54 |
24 |
21 |
|
Island |
Portugal |
18 |
23 |
58 |
|
Danmark |
Kypros |
53 |
24 |
22 |
|
Norge |
Danmark |
46 |
26 |
27 |
|
Kypros |
Island |
48 |
25 |
27 |
|
Portugal |
Norge |
50 |
24 |
25 |
|
Island |
Danmark |
27 |
26 |
47 |
|
Norge |
Island |
63 |
22 |
14 |
|
Kypros |
Portugal |
23 |
24 |
54 |
|
Island |
Kypros |
36 |
27 |
36 |
|
Danmark |
Norge |
38 |
27 |
35 |
|
Portugal |
Island |
70 |
19 |
11 |
|
Kypros |
Danmark |
31 |
27 |
42 |
|
Norge |
Kypros |
56 |
24 |
20 |
|
Danmark |
Portugal |
30 |
26 |
43 |
Plasseringsjanser per lag(%)
|
Lag/Plass |
1. |
2. |
3. |
4. |
5. |
|
Portugal |
17 |
32 |
30 |
17 |
4 |
|
Norge |
56 |
26 |
12 |
5 |
1 |
|
Danmark |
21 |
29 |
29 |
17 |
4 |
|
Kypros |
5 |
11 |
22 |
40 |
22 |
|
Island |
1 |
2 |
7 |
21 |
69 |
Med utgangspunkt i FIFA-rankinga er Portugal fortsatt ansett for å være det beste laget i gruppa, og er favoritt i alle sine resterende kamper. Men med sitt dårlige utgangspunkt er det mest sannsynlig at Portugal ikke klarer å ta igjen Norge.
Har dette noe med forskning å gjøre? Fotballberegningene er en lek med tall for å spre blest om faget. Men de illustrerer hvordan avanserte beregninger kan utføres, for eksempel ved estimering av fiskebestander eller sannsynligheten for at en bank går konkurs. I begge tilfeller er stokastisk simulering, altså å simulere virkeligheten på en datamaskin, et uvurderlig verktøy.
Beregningene ble oppdatert 8.9.2010, etter Norges hjemmekamp mot Portugal, og blogginnlegget er skrevet sammen med Anders Løland.
| Magne Aldrin |
|

1 kjem oftast først
august 31, 2010 - 11:07 — Ragnar HaugeI språk er det velkjent at bokstavane ikkje vert brukt like ofte. Spesielt for første bokstav er det stor variasjon i kor ofte dei ulike bokstavane vert nytta. Reint intuitivt vil ein vel tenka at det ikkje er slik for tal – det er like mange tal som startar med 1 som det er tal som startar med 2 eller 3 og så vidare. Reint teknisk er det også slik, med stringente matematiske prov.
Men dersom ein ser på tal vi brukar, vil det vera fleire som startar med 1 enn med noko anna tal. Til dømes kan ein sjå på folketalet i verda frå 1800 og til i dag, ein periode på 210 år. I 120 av desse, frå 1800-1920 var folketalet mellom 1 og 2 milliardar, og starta dermed med 1.
Startpunktet er rett nok heldig vald, sidan det startar med 1, men det forklarer likevel ikkje kvifor folketalet startar med 1 i over halve perioden.
Dersom ein i staden ser på folketalet i USA i same tidsintervall finn ein at det startar med 1 i intervallet 1820-1845 (10-20 millionar) og 1915-1970 (100-200 millionar), altså 80 av 210 år, igjen ei klar overrepresentasjon. Ser ein berre på menn, og reknar med at desse utgjer om lag halvparten, får vi tal som startar på 1 frå 1845-1870 og 1970-2010, altså 65 år, framleis nesten ein tredjedel av åra.
Dette fenomenet er kjent som Benfords lov, etter fysikaren Frank Benford, som oppdaga og forklarte det på 1930-talet. Poenget er at denne samanhengen gjeld for fenomen som i nokon grad er utsett for eksponensiell vekst.
Folketal er eit typisk slik fenomen. Inntil relativt nyleg hadde dei aller fleste land eksponensiell vekst i folketalet, og for verda totalt og USA gjeld dette framleis. Det tyder at i løpet av eitt år veks folketalet med ein gitt prosent. Å auka folketalet i verda frå 1 til 2 millardar krev ei fordobling av folketalet, medan å gå frå 2 til 3 berre er 50% auke, og dermed skjer mykje raskare.
Reint presist seier Benfords lova at 30,1% av tala skal starta med 1, 17,6% med 2, 12,5% med 3, og så daler det jamt inntil berre 4,6% av tala startar med 9. Dersom ein ser på folketala i alle verdas land er dette ikkje ei dårleg tilnærming.
Grunna inflasjonseffektar vil også alle tal i økonomi følgja denne loven. Uavhengig av om det er prisen på brød, medianløn eller BNP vil ein over tid finna at dei oftast startar med 1. I USA er store avvik frå denne loven i økonomital brukt som indisium i rettssaker om økonomisk kriminalitet (t.d. i State of Arizona v. Wayne James Nelson, sjå http://www.journalofaccountancy.com/Issues/1999/May/nigrini). Poenget er at når folk diktar opp tal vil dei stort sett starta like ofte med kvart siffer, og dermed ikkje følgja Benfords lov.
Som illustrert i eksempelet med folketal i USA, der fenomenet var der uavhengig av om ein såg på heile eller halve folketalet, er denne loven uavhengig av måleeining. Dersom ein ser på dei 60 høgaste bygningane i verda har 43% av dei høgd som startar med 1 dersom ein måler i meter. Dersom ein skiftar til fot er det 30%, altså også då klart flest som startar med 1.
Det er også andre moment som gjer at flest tal startar med 1, men desse er svakare. Dersom ein ser på alderen til folk vil den også som oftast starta med 1, men dette skuldast eit anna fenomen, nemlig at 1 kjem først. Dermed vil alle som vert 2 ha vore 1, alle som vert 20 har vore 10-19, og dersom ein vert gamal nok vil alle dei siste åra starta på 1. Dette er ikkje Benfords lov, men ei favorisering av 1 som likevel gjer seg gjeldande for alt som tel opp frå 0 og ikkje kjem til veldig store tal.
| Ragnar Hauge |
Eg har jobba på Norsk Regnesentral sidan 1995. Mesteparten av tida har eg jobba med modellering av bergartar i oljereserervoar, men eg har etterkvart også mykje erfaring med bruk av seismiske data. Ut over det faglege er eg interessert i det aller meste, i alle fall frå eit teoretisk synspunkt. |
